Mängel in der Datenqualität sind bei Banken wohl eines der größten Hindernisse einer effektiven Geldwäscheprävention. Laut einer 2020 in den USA veröffentlichten Umfrage sind 63% der AML-Verantwortlichen der Ansicht, sich auf die ihnen vorliegenden Daten nicht wirklich verlassen zu können. Erfahrungsgemäß ist die Situation in europäischen Banken nicht anders.
AML-Verantwortliche haben meist keine ausreichende Kontrolle über die Qualität der von ihnen auszuwertenden Daten. Sie sind allerdings für die Folgen von Mängeln in der Geldwäscheprävention, die durch schlechte Datenqualität verursacht sind, verantwortlich.
Unrichtige Daten führen beispielsweise häufig zu „False Positives“ in den Prüf- bzw. Monitoring-Systemen sowie zu unnötige Due-Diligence-Prüfungen durch die AML-Mitarbeiter. Auch kann das Übersehen eines „True Positive“ zu hohen Strafzahlungen und Reputationsschäden führen. Als besondere Herausforderung sei bei mangelhaften Kundendaten auch der Abgleich mit Sanktionslisten genannt.
Neue AML-Screening-Plattformen beziehen daher künstliche Intelligenz mit ein und berücksichtigen Erkenntnisse aus algorithmischem Lernen. Das Ergebnis sind Compliance-Daten von erheblich besserer Qualität. Diese Systeme können in den Daten vielfach auch Duplikate, inkonsistente Formate, Dummy-Daten und nicht in dedizierten Namensfeldern abgelegte Kundennamen berücksichtigen und auf diese Weise die Zahl der generierten „False Positives“ und das Risiko, tatsächlich verdächtige Transaktionen nicht zu erkennen, erheblich senken.
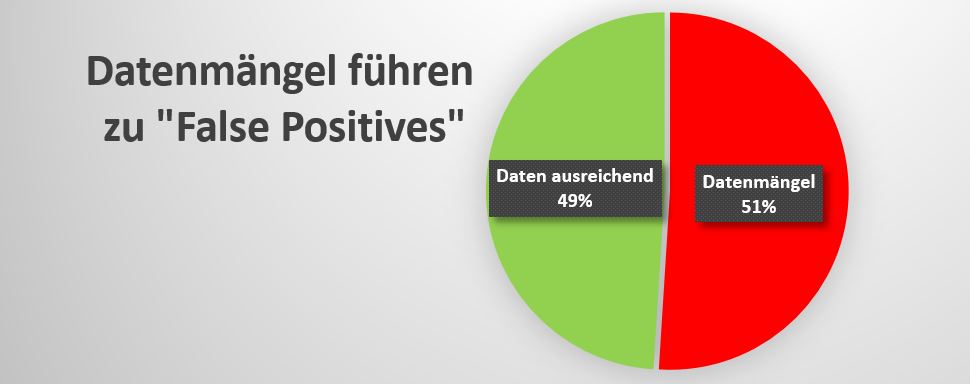
Erfahrungsgemäß ist Datenqualität auch in europäischen Banken ein heißes Thema. Es kann wohl angenommen werden, dass die in den USA genannten Mängel auch bei uns in ähnlicher Häufigkeit auftreten. Insgesamt wurde in den USA eine durch Datenmängel verursachte Fehlerquote von 51% genannt, wobei vor allem folgende Mängel zu „False Positive“-Alerts führten:
- Kundennamen in Adressfeldern – 9,3%
- Unpassendes Datenformat – 7,6%
- Fehlerhafte Speicherung des Namens – 7,5%
- Inkonsistentes Länderformat – 6,2%
- Dummy-Daten – 5,7%
- Mehrere Namen im Namensfeld – 4,9%
Quelle: APA-OTS, OTS0170, 15. April 2019, 19:51
TIPP 1:
Am besten wird wohl sein, zu „schulen, schulen, schulen…“ – also die Sensibilität für die Tragweite schlechter Datenqualität zu fördern!
TIPP 2:
Vertriebsmitarbeiter stehen unter großem Leistungs- und Zeitdruck. Wie wäre es, gute Datenqualität zu belohnen und entsprechende Kriterien in die Bonusbemessung einzubauen?